edited: fix link for wrapper repo
This is a repost from openrobotics.zulipchat.com that I made earlier, it was suggested I post here, so here goes…
So, over the past couple days we’ve been working on getting Depth Anything 3 (DA3 - the new monocular depth estimation model from ByteDance) running with ROS2. For those unfamiliar, Depth Anything 3 is basically a neural network that can estimate depth from a single camera image - no stereo rig or LiDAR needed. It’s pretty impressive compared to older methods like MiDaS.
Depth Anything V3 paper: [2408.02532] Singularity categories of rational double points in arbitrary characteristic
Official DA3 repo: GitHub - ByteDance-Seed/Depth-Anything-3: Depth Anything 3
Our GitHub DA3 ROS2 Wrapper Repo:
Here’s what the system looks like running on our Jetson: GitHub - GerdsenAI/GerdsenAI-Depth-Anything-3-ROS2-Wrapper: ROS2 wrapper for Depth Anything 3 (https://github.com/ByteDance-Seed/Depth-Anything-3)
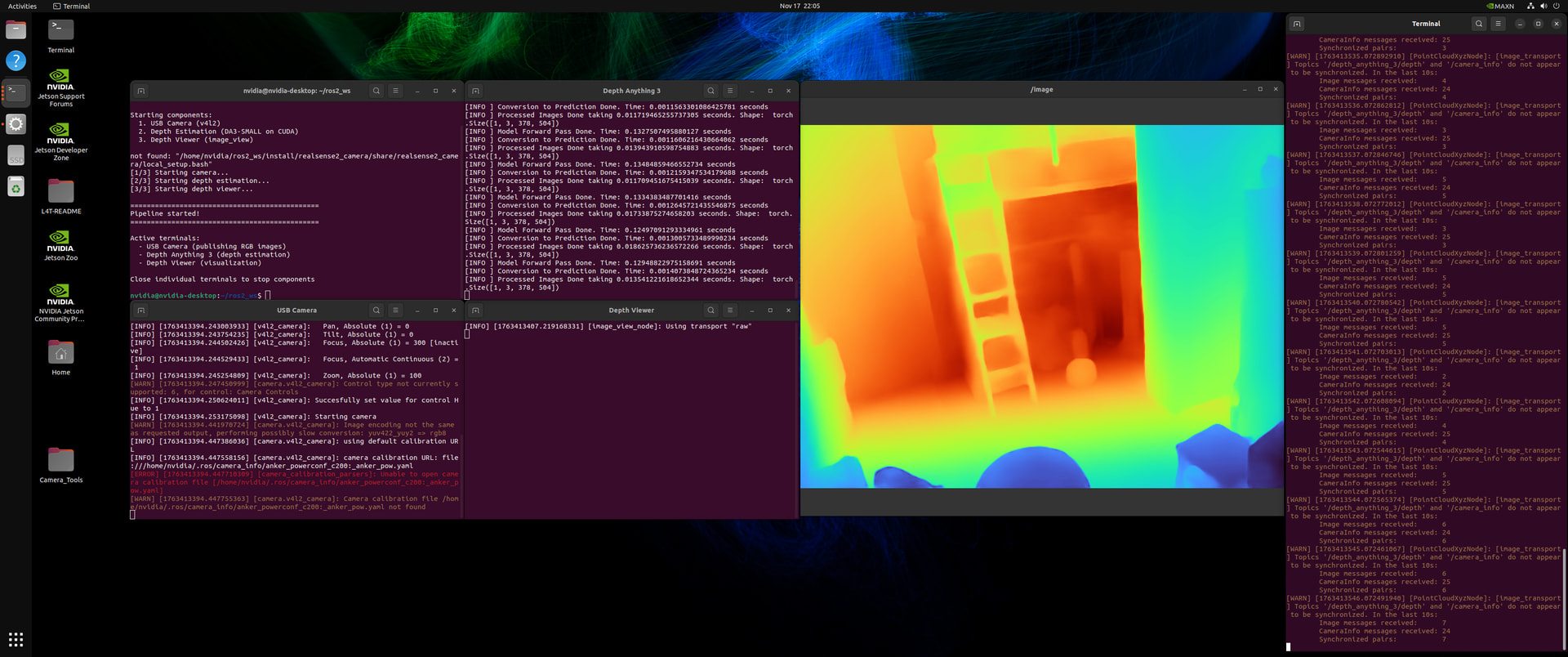
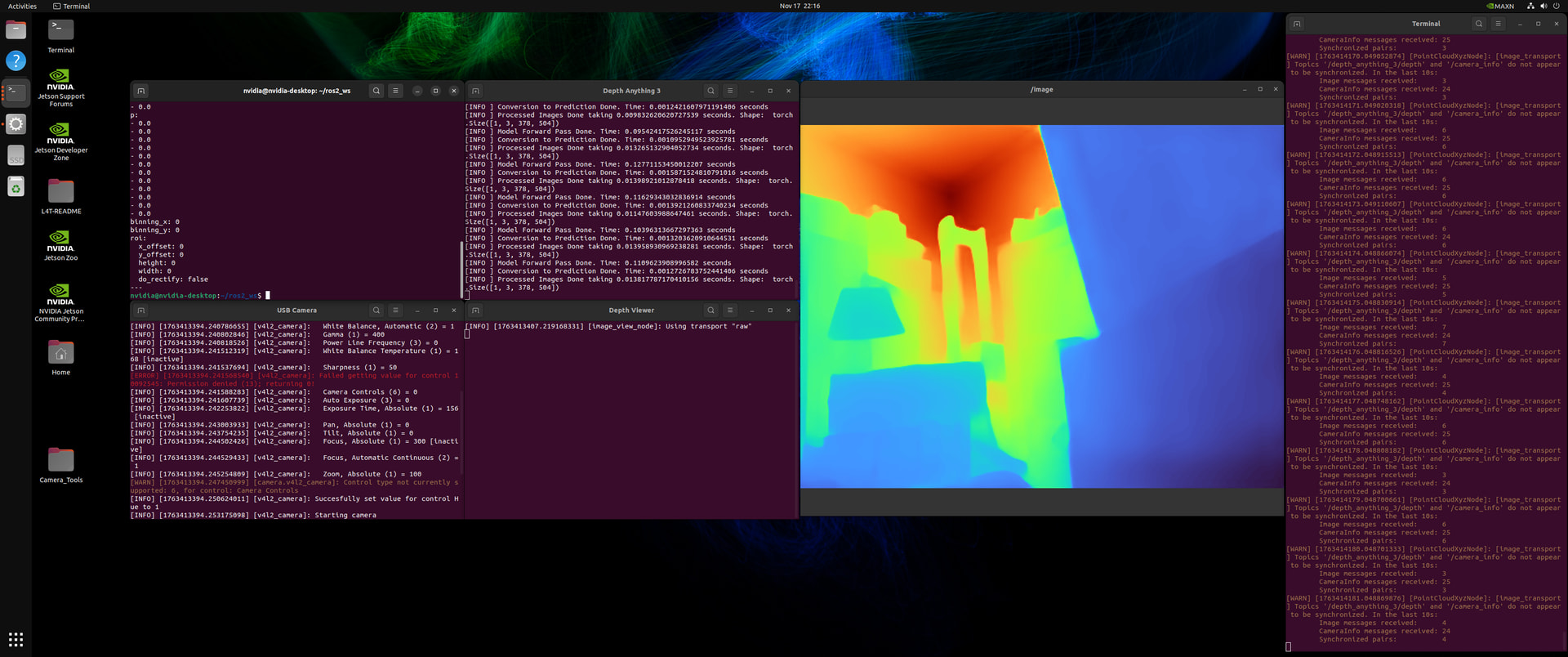
You can see three terminals:
- Left: USB camera node publishing at 640x480 @ 30 FPS
- Middle: Depth estimation running with the colored depth output
- Right: Depth viewer displaying the results
The depth visualization uses a turbo colormap (blue = close, red/orange = far). The quality is honestly better than we expected for monocular depth.
Platform: NVIDIA Jetson AGX Orin 64GB (Syslogic A4AGX64 industrial variant)
- OS: Ubuntu 22.04 + JetPack 6.2.1
- CUDA: 12.6
- ROS2: Humble
Camera: Anker PowerConf C200 2K USB webcam
- Running at 640x480 resolution
- 30 FPS output (though depth processing can’t keep up, feel free to help!!
 )
)
Software:
- PyTorch 2.8.0 (Jetson-optimized from nvidia-ai-lab)
- Depth Anything 3 SMALL model (25M parameters)
- Standard v4l2_camera for USB input
Current Performance (This is Where We Need Help)
Here’s what we’re seeing:
Inference Performance:
- FPS: 6.35 (way slower than we hoped)
- Inference time: 153ms per frame
- GPU utilization: 35-69%
- RAM usage: ~6 GB (out of 64 GB available)
Is PyTorch the problem? We’re running standard PyTorch with CUDA. Would TensorRT conversion give us a significant speedup? Has anyone done DA3 → TensorRT on Jetson?
Memory bandwidth? Could we be hitting memory bandwidth limits moving tensors around?
Is the model just too big for real-time? The SMALL model is 25M params. Maybe we need to quantize to FP16 or INT8?
FP16 precision - The Ampere GPU supports FP16 tensor cores. Depth estimation might not need FP32 precision.
Optimize the preprocessing - Right now we’re doing image normalization and resizing in Python/PyTorch. Could we push this to GPU kernels?
Has anyone done any of this successfully? Especially interested if anyone’s gotten DA3 or similar transformers running fast on Jetson.
The paper claims real-time performance but they’re probably testing on desktop GPUs. Getting this fast on embedded hardware is the challenge.
But, we got it working, which is cool, but 6 FPS is pretty far from real-time for most robotics applications. We’re probably doing something obviously wrong or inefficient - this is our first attempt at deploying a transformer model on Jetson.
Contact: GerdsenAI · GitHub
License: MIT
Feel free to contribute! ![]()