As part of the upcoming ROS2 Lyrical Luth release, the client library working group has been planning to mainstream an EventsExecutor implementation as the new default executor in rclcpp. The current experimental implementation is limited by its inability to properly handle simulation time, unlike the EventsCBGExecutor implemented by @JM_ROS over at Cellumation, which can properly handle sim time as well as offering a multithreaded mode. As a first step towards mainstreaming an EventsExecutor implementation, we ran an extensive set of benchmarks built on top of iRobot’s ros2-performance framework (Keep an eye out, as we are hoping to eventually open-source the full benchmark test suite!)
This post will serve as a deep dive into the performance characteristics of the two executors as well as a jumping off point for discussing the overall state of executors (and middleware implementations) in ROS2. (This is a cleaned-up rewrite of a github gist that I originally put all the benchmark info into)
Some notes about the benchmarks:
- Benchmark environment:
upstream ROS rolling docker container running on an x86 developer laptop under minimal load
rclcpp rolling:b14af74a4c9b8683e72b15d61d0ed9121d883973
cm_executors:783a5e329ee8b04abfa3b3397532e979576a2b1f
ros2_performance:4528f43410922379b8da501630d9d938046e48e8 - This suite of benchmarks was run at least 3 times per implementation, to ensure consistent results. For brevity’s sake, we’ll stick to one graph each for this analysis, but the full set of results will be made available elsewhere.
- ipc_on = running with intra-process mode
- In the latency tests, max latency signifies the highest single latency measurement taken for that message size. We didn’t do any outlier filtering on this dataset (aside from the high latencies from the first few seconds), so this value is known to have more consistent variation.
- In the process of producing these benchmarks, we discovered a bug with the generation of clients/services single and multi process CPU usage. Graphs were generated for each, but the underlying data represents just the single process benchmark so we’ll only cover single process clients/services CPU usage.
- There were a few tests we couldn’t run with the EventsCBGExecutor because of freezes or crashes, and so those tests were also omitted for the upstream EventsExecutor.
- For a more 1:1 comparison between the two executors, the EventsCBGExecutor was fixed to use just one thread.
Takeaways, tl;dr:
-
Despite some initial concerns about marginally higher CPU usage for the EventsCBGExecutor compared to the experimental EventsExecutor, there doesn’t appear to be too much of a difference across all the characteristics we tested, with the following exceptions
- EventsExecutor performed slightly better on the long running pub/sub CPU usage test.
- EventsCBGExecutor performed slightly better on the long running actions CPU usage test.
-
Both executors demonstrate memory leaks in the longer running pub / sub and actions tests. After further investigation, the SingleThreadedExecutor and MultiThreadedExecutor also show a climb in memory for pub/sub, while actions remain stable for the SingleThreadedExecutor (except for rmw_zenoh).
-
As we step through the benchmarks, I’ll point out any differences between the executors as they appear.
CPU Usage - Pub/Sub - Single Process

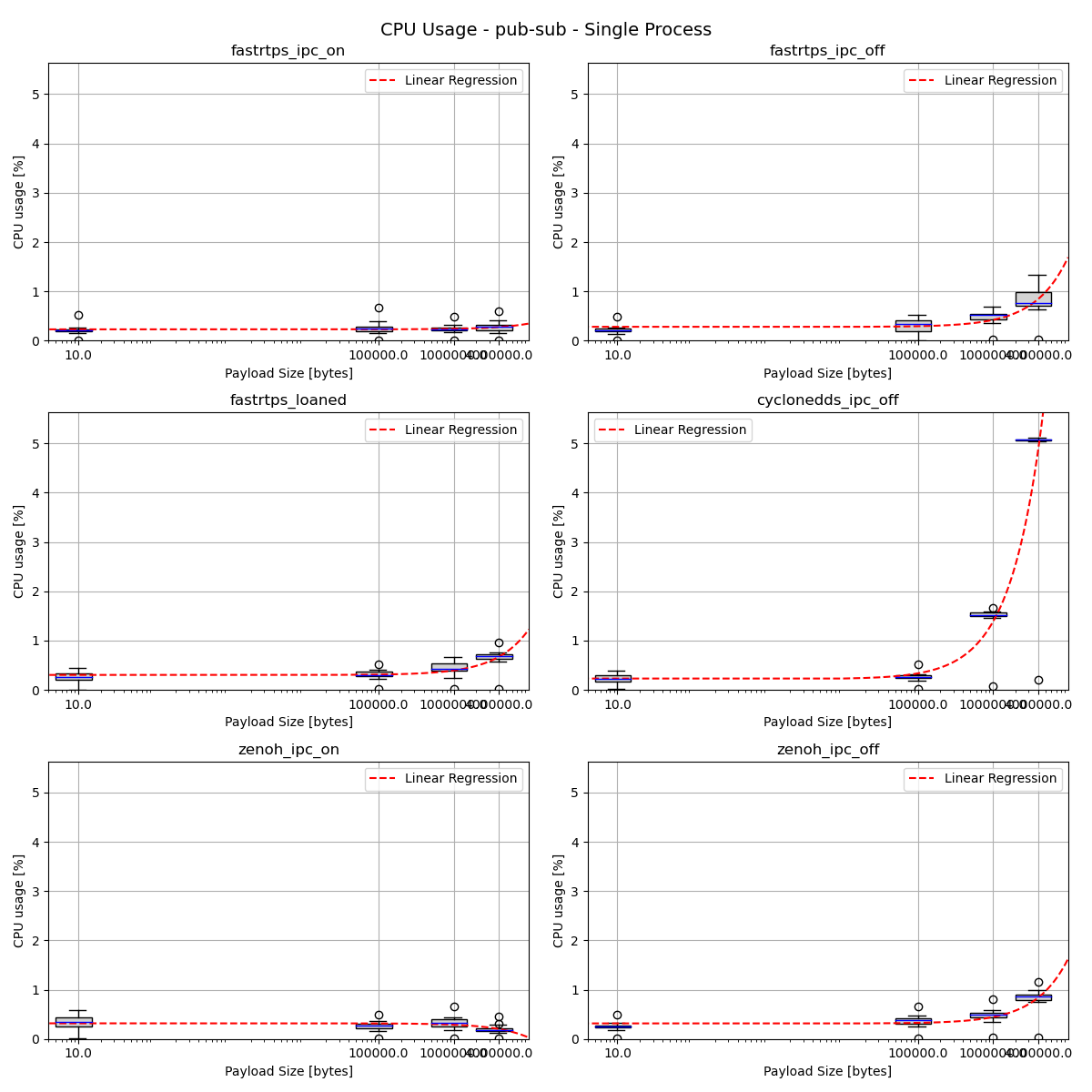
We can see that the max y axis for the second graph is way higher due to CycloneDDS seemingly causing the test to consume way more CPU at higher message payloads, amidst otherwise highly comparable results. This difference in CPU for CycloneDDS specifically was consistent across all runs of the benchmark suite.
CPU Usage - Pub Sub - Multi Process
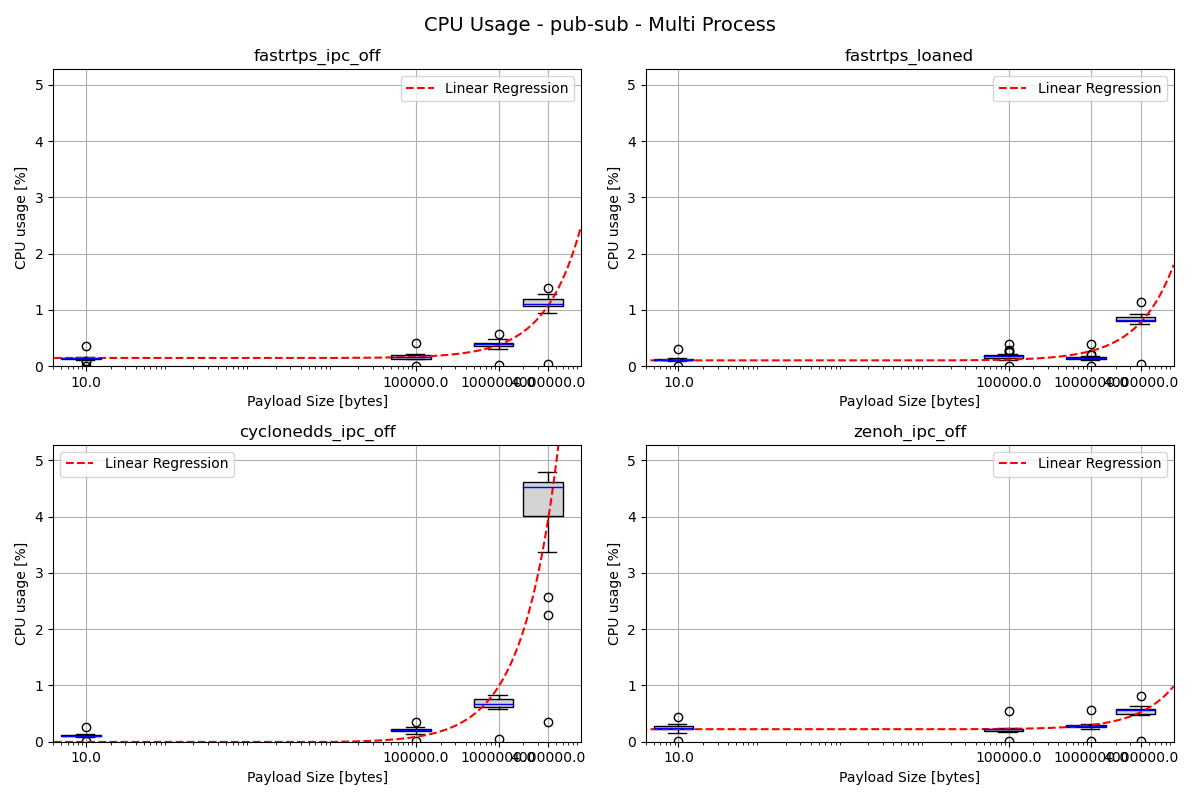

Interestingly, in multi-process mode the climb to ~4-5% of a core at larger payload sizes is now consistent for both executors when running CycloneDDS. Otherwise, both executors seem to put up similar results here.
CPU Usage - Services / Clients - Single Process


CPU Usage - Pub/Sub - Long Running Test (10m)


The usage pattern for both executors appears fairly similar, with the EventsExecutor averaging around 0.05 - 0.1% less CPU usage than EventsCBGExecutor in most runs.
CPU Usage - Services / Clients - Long Running Test (10m)
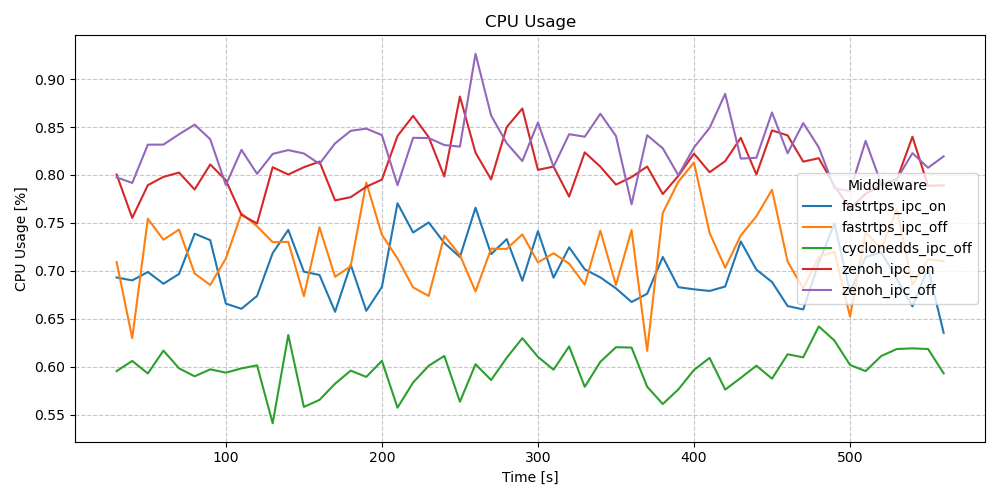
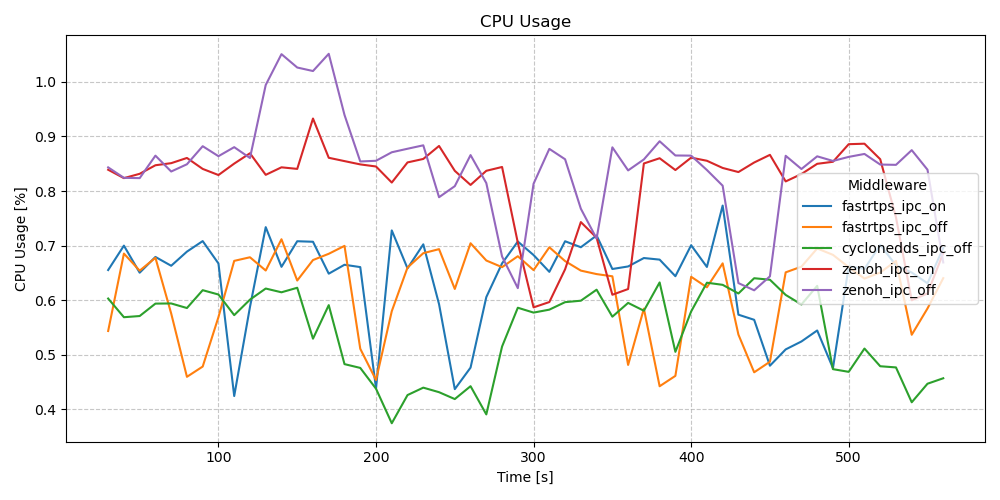
CPU Usage - Actions - Long Running Test (10m)
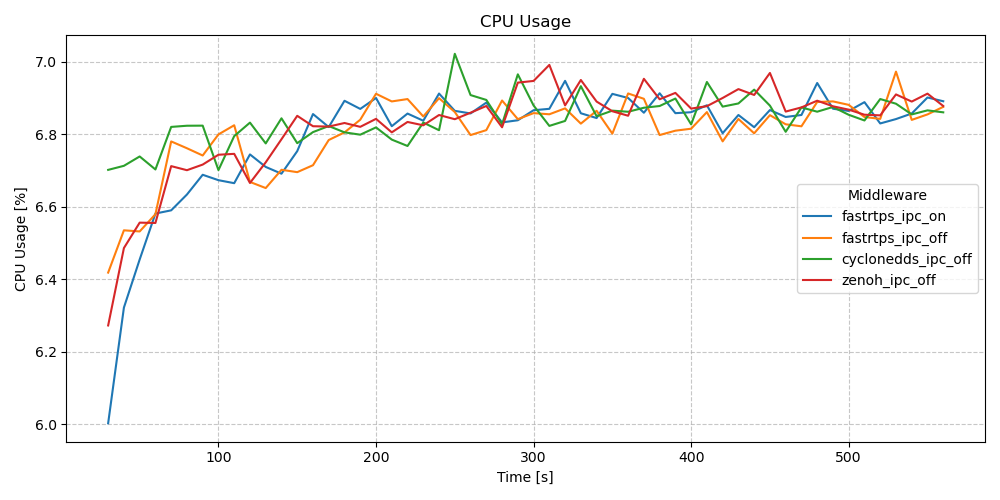

We again see a similar usage pattern between the two executors, but with the EventsCBGExecutor consistently maxing out at ~2% less CPU than the EventsExecutor and with a smoother looking graph.
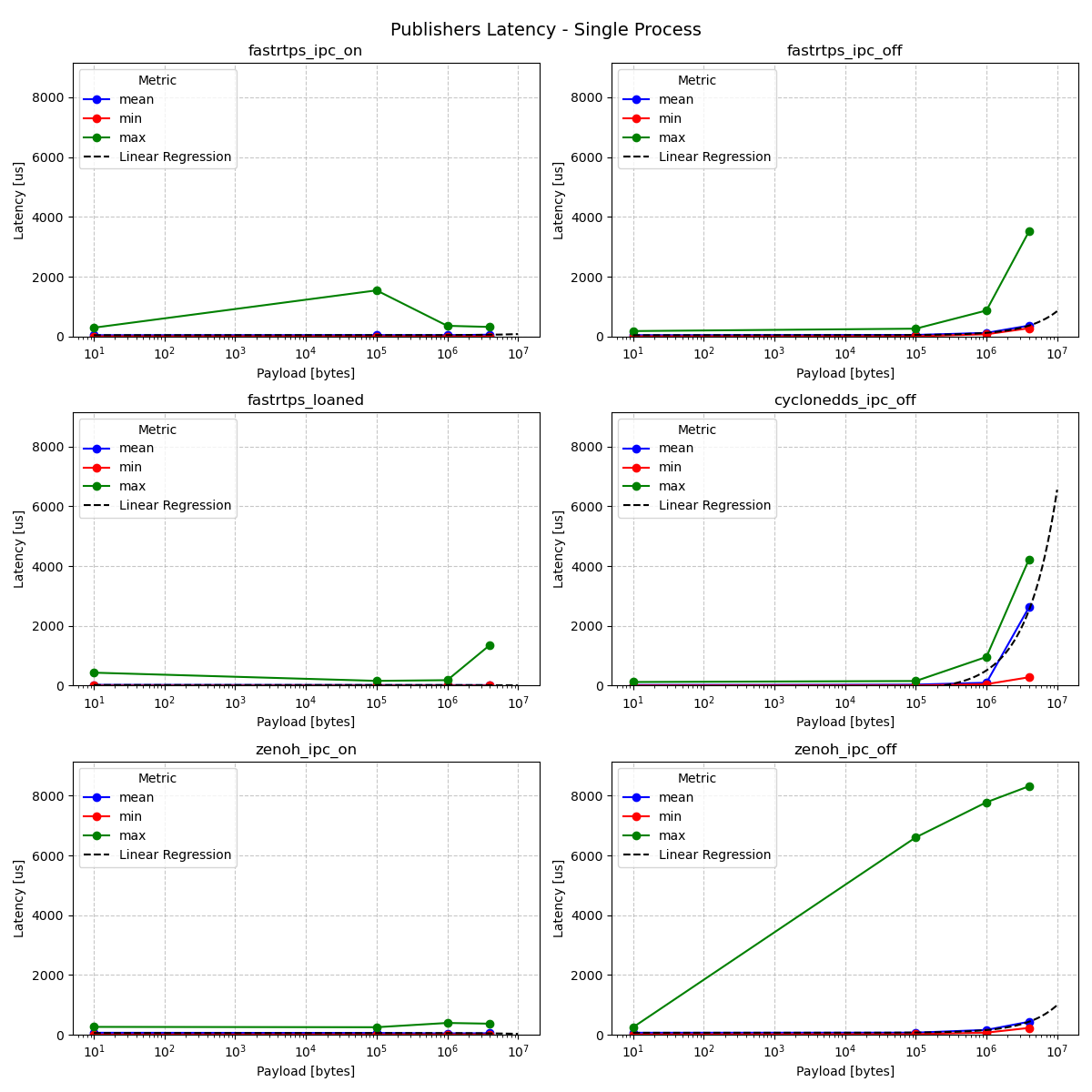
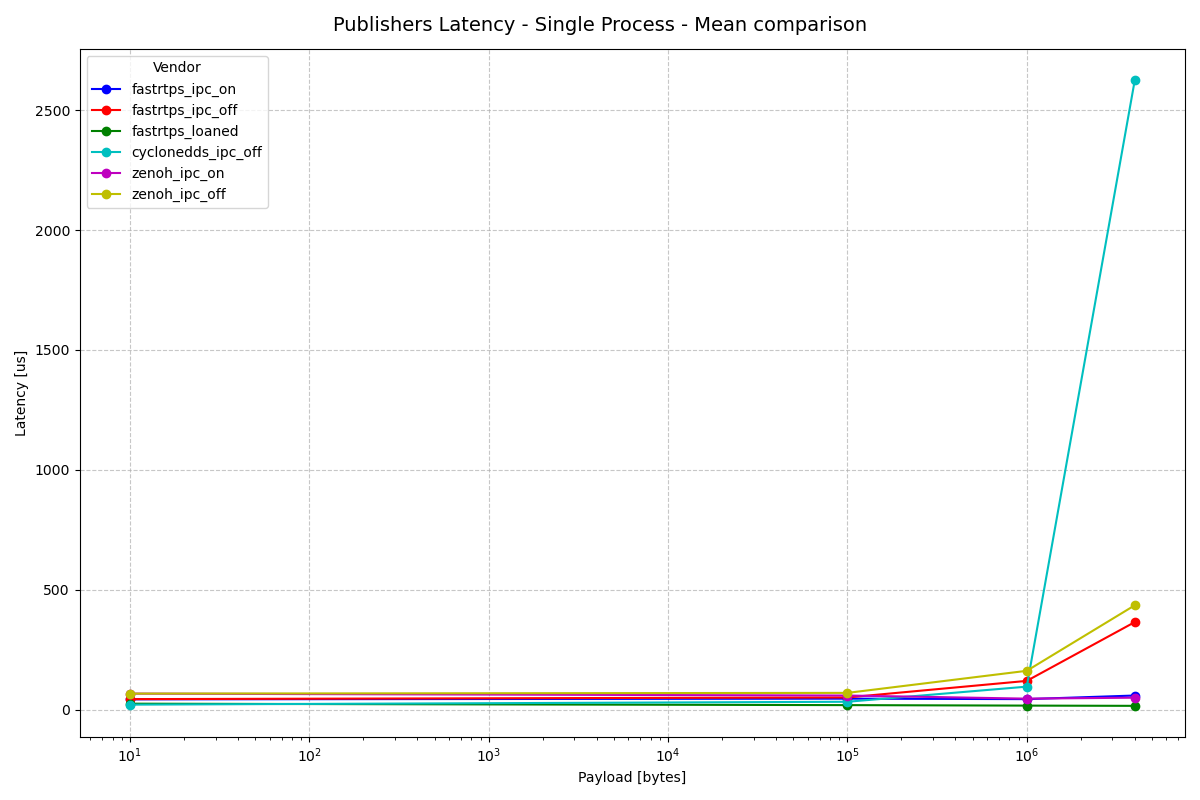
Publisher Latency - Single Process


Subscriber Latency - Single Process


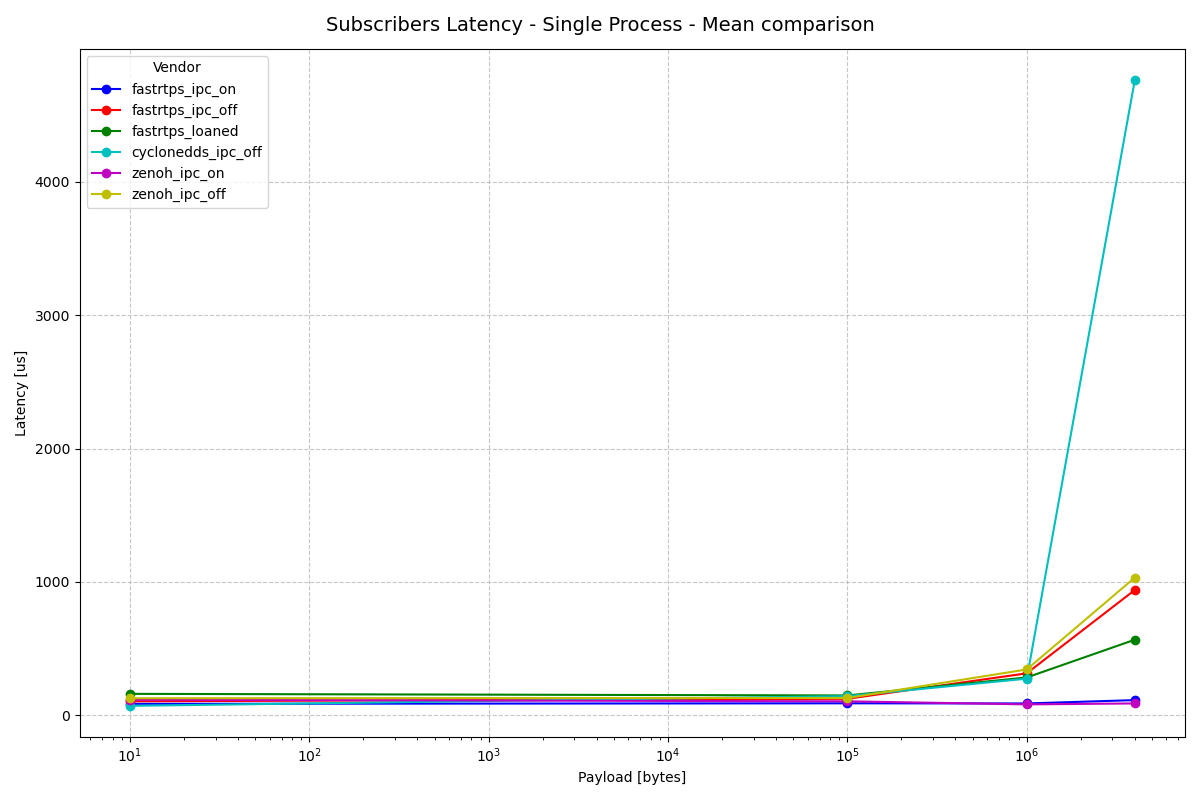
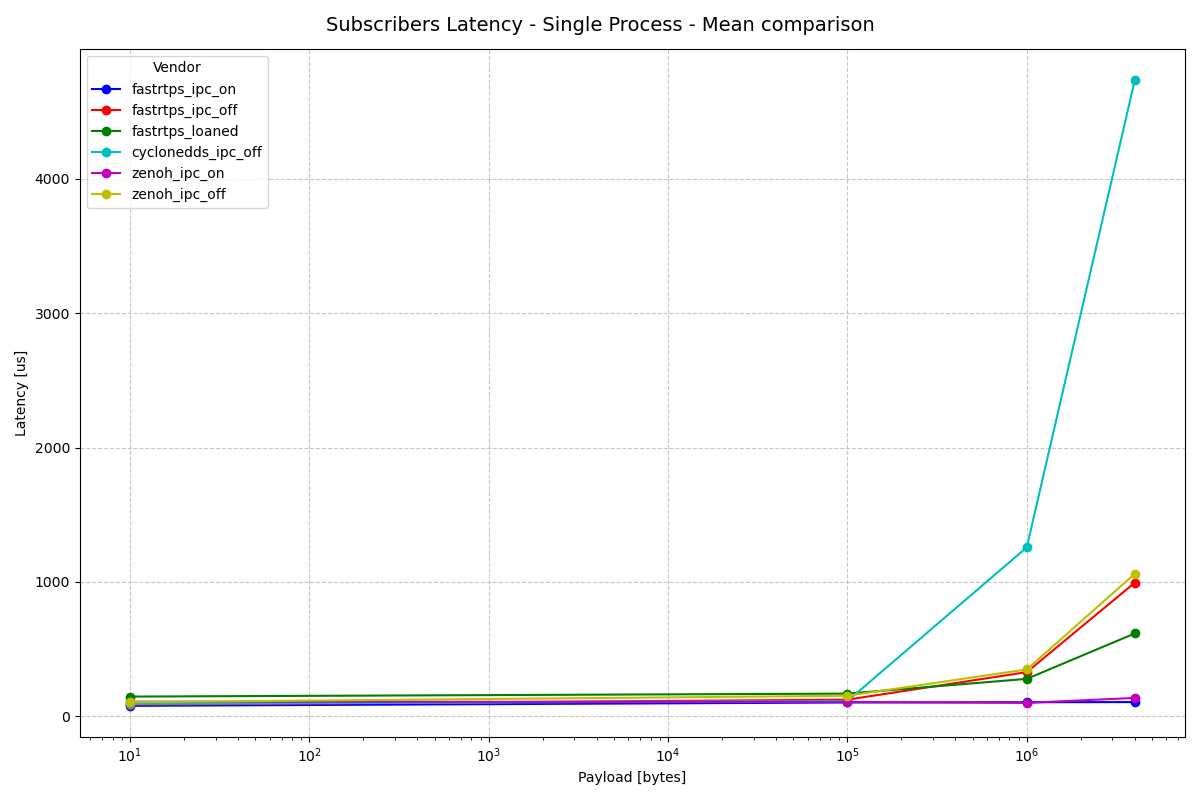
Huge differences in max latency aside, we see comparable results here between the two executor implementations for both pub and sub latency. The mean comparison demonstrates extremely similar results, including CycloneDDS’s extreme latency increases at higher payload sizes. The latency increases appear to exaggerate with slightly smaller payloads in EventsCBGExecutor than in EventsExecutor.
Publisher Latency - Multi Process




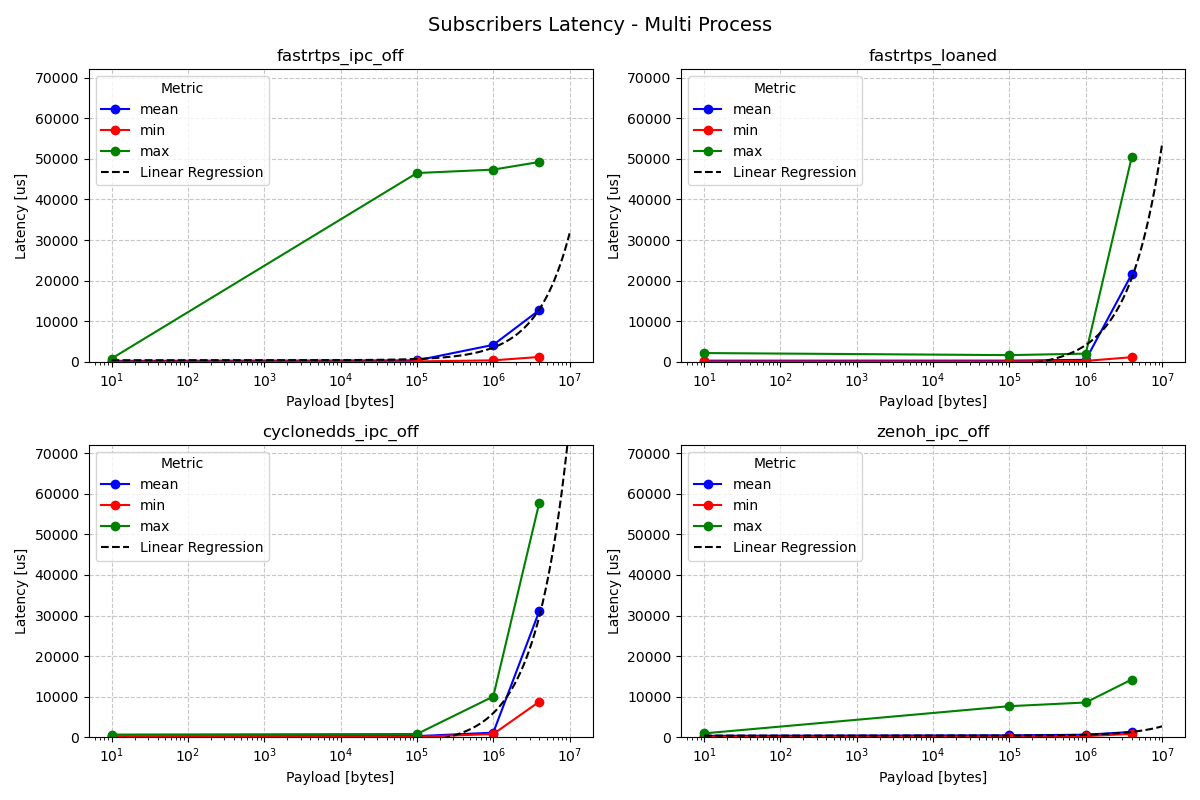
Subscriber Latency - Multi Process



Publisher Latency - Long Test (10m)
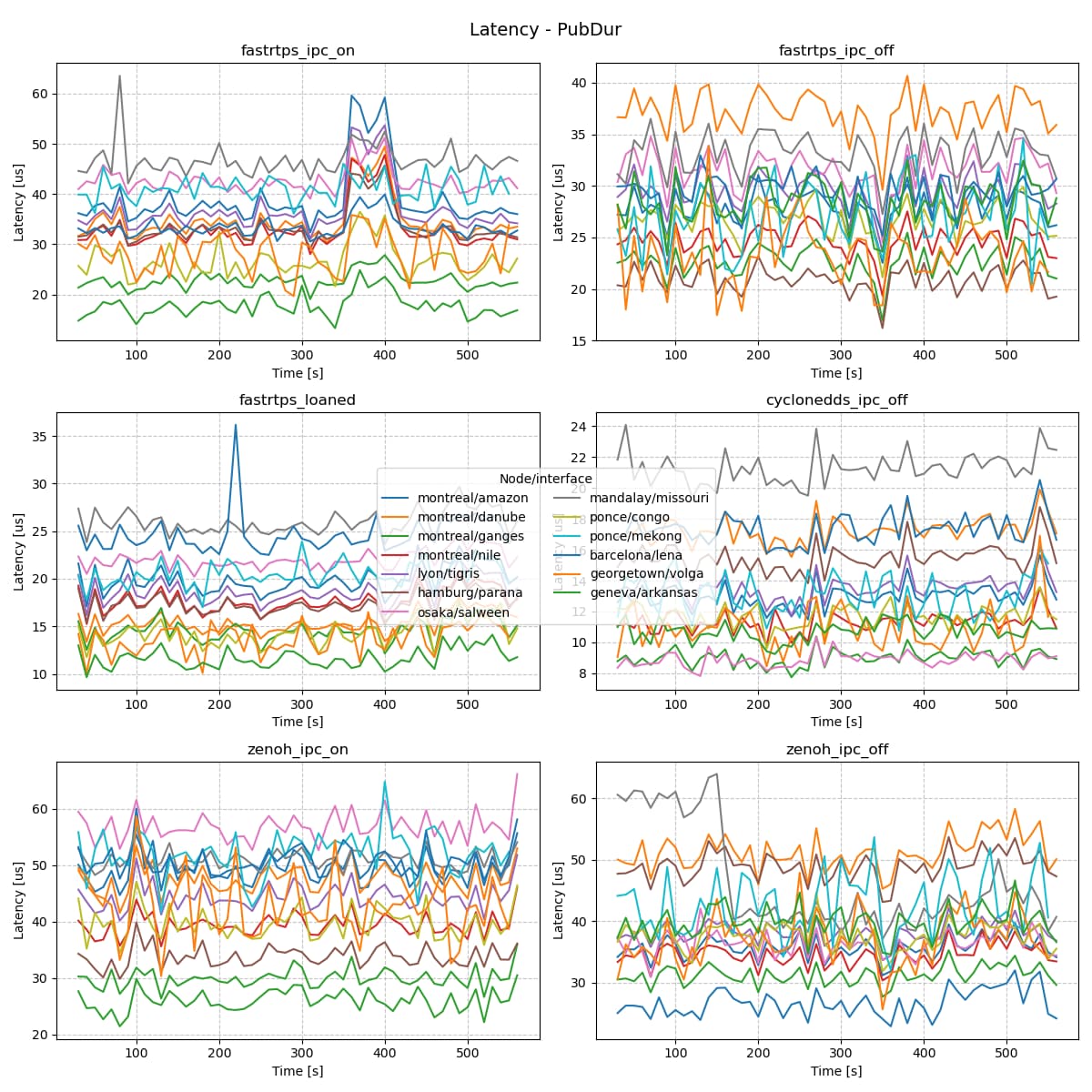

Subscriber Latency - Long Test (10m)


Memory Scaling Comparison

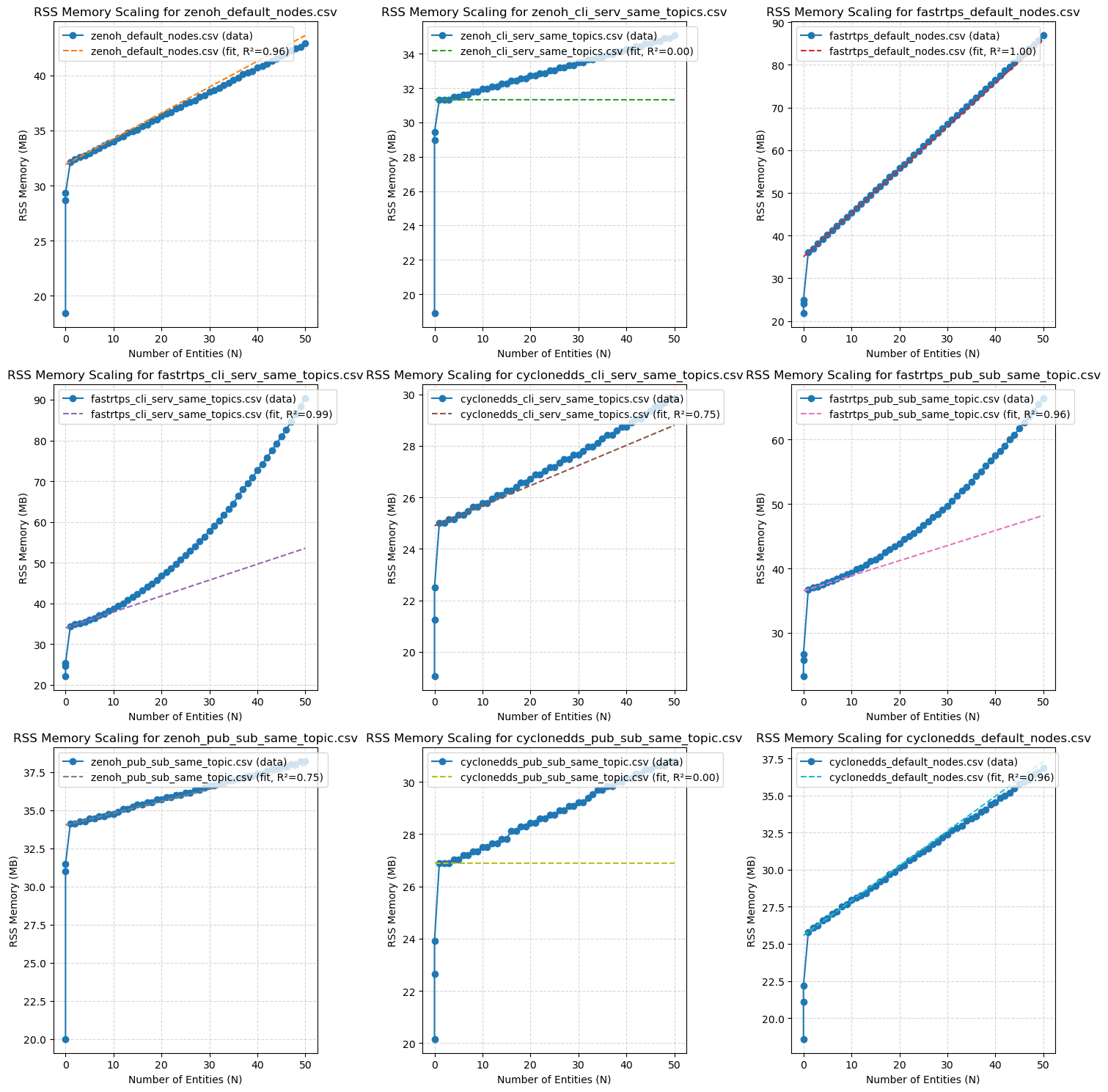
RAM Usage - Pub/Sub - Long Test (10m)
| rclcpp::experimental::EventsExecutor | cm_executors::EventsCBGExecutor |
|---|---|
| rclcpp::SingleThreadedExecutor | rclcpp::MultiThreadedExecutor |
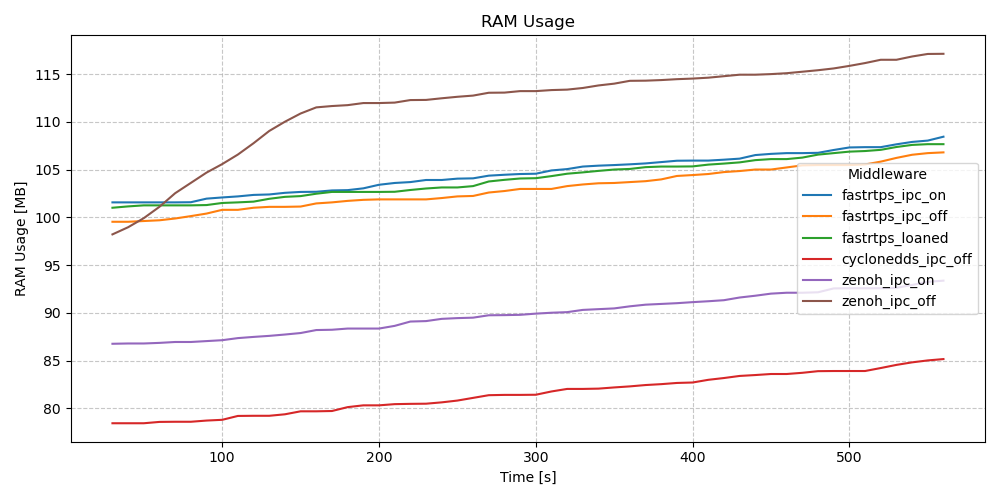



Not much difference between the two events executors. This appears to expose a slow climbing memory leak in the client library side, either with both of these executor implementations or in some other part of the code. This leak appears consistent across all RMWs and across all runs of all four executors (single threaded, multi threaded, EventsExecutor, EventsCBGExecutor). Zenoh without intraprocess shows a much sharper increase the first few minutes in.
RAM Usage - Services/Clients - Long Test (10m)
| rclcpp::experimental::EventsExecutor | cm_executors::EventsCBGExecutor |
|---|---|
| rclcpp::SingleThreadedExecutor | rclcpp::MultiThreadedExecutor |



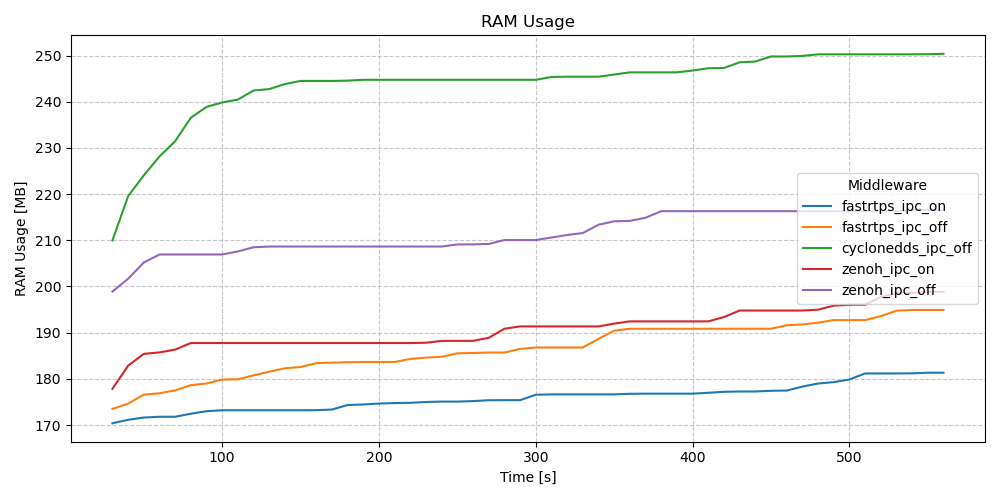
Not much different across the executors, with the multi-threaded executor exhibiting much higher overall baselines in RAM usage. We again see RAM climbing for all four, but the rate of usage appears to level out about 5 or so minutes into the tests.
RAM Usage - Actions - Long Test (10m)
| rclcpp::experimental::EventsExecutor | cm_executors::EventsCBGExecutor |
|---|---|
| rclcpp::SingleThreadedExecutor | rclcpp::MultiThreadedExecutor |


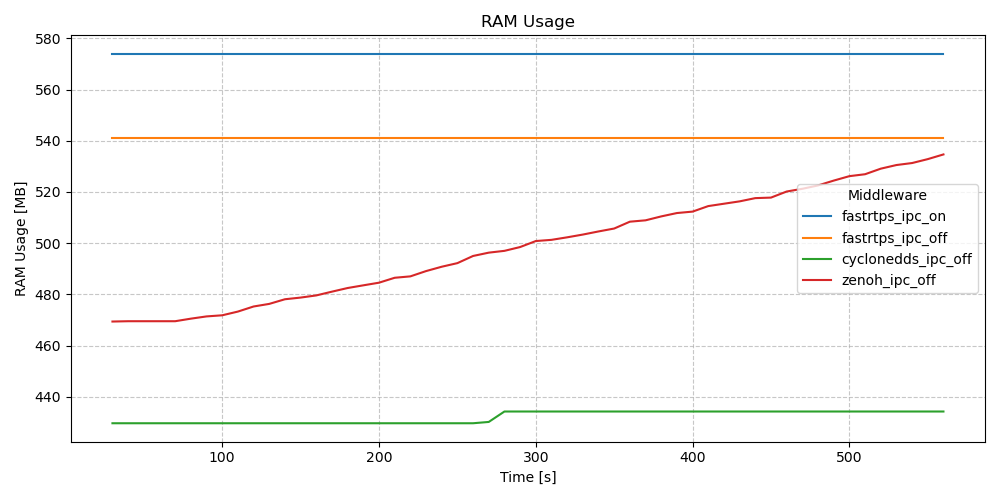

Both EventsExecutor implementations demonstrate significant memory leaks during the long running actions tests. The multi-threaded executor’s usage pattern looks similar to clients / services. In the SingleThreadedExecutor, rmw_zenoh appears to exhibit leaks unlike the other tested RMWs.