The goal of this project is to translate the ROS 2 documentation into multiple languages. Translations are contributed via the Crowdin platform and automatically synchronized with the GitHub repository. Translations can be previewed on GitHub Pages.
And I believe this l10n project can address the above need.
If translators want to translate a new language, they just need to open an issue for the requested language. Take the following topic in CMake Discourse for reference:
Can you help me understand why you would fork the ROS documentation and add your own localization instead of contributing localization capabilities back to the canonical ROS documentation?
We already have a place where localized documentation would slot into docs.ros.org but we haven’t had the contributor resources to make that happen (i.e. the “en” in https://docs.ros.org/en/jazzy/ is for English). We desperately need more contributors to the ROS documentation so we can roll out features like localization.
I’m also concern about out of date and incorrect forked copies of the documentation surfacing higher than the canonical documentation in Google searches. This is already happening in some cases and causing confusion for new users.
As for why I don’t contribute the localization capabilities back to upstream, it’s because, from the practical maintenance experience, separating the tasks of “updating the English sources” and “maintaining multilingual translations” into their own respective repositories can “reduce maintenance costs”. The following Sphinx-based documentation projects maintain their multilingual translations in this manner:
On the other hand, if the upstream wants to build the translated ROS 2 documentation with the well-prepared .po files from the downstream, it can place the .po files wherever it wants using the following command:
On the other hand, if the upstream wants to build the translated ROS 2 documentation with the well-prepared .po files from the downstream, it can place the .po files wherever it wants using the following command
That’s great. Can you speak to how we could integrate this workflow into the existing ROS documentation and roll it out to everyone? The reason this is a tricky problem for us is that we need to find a strategy that scales to dozens, if not hundreds, of languages spoken by ROS users. We also have to figure out how to address the on-going maintenance burden with respect to both translation improvements and underlying documentation improvements (i.e. how would we upstream a new tutorial written in Chinese to the canonical English docs and then roll it back out to downstream users in other languages). Quite frankly, automated in-browser translation tools are generally good enough that we’ve been kicking this can down the road for awhile.
I am also trying to understand the tool chain you are using for this project, as these translations don’t appear to be done by humans. I don’t have time right now to do a deep dive, but from what I gather most of the translation has been performed by the CrowdIn platform which appears to have significant cost associated with it. The translation quality also seems spotty. Your CI widgets seem to claim that the translation is mostly complete but I clicked through all of the intermediate tutorials and none of them appear to be in Chinese.
I’m also concerned about out of date and incorrect forked copies of the documentation surfacing higher than the canonical documentation in Google searches. This is already happening in some cases and causing confusion for new users.
I would also love an answer here as this is something that is already causing everyone using search engines significant headaches.
Anyway, I don't want to discourage people from working on translations, they are exceptionally important. However, this is a really really tricky problem and also a significant long term commitment. My opinion is that if we are going to do it, and do it right, we'll need a significant community effort. What I would really love to see is a community group generate a strategy document that outlines how we can tackle this problem for the entire ROS community.
Since you mentioned a number of issues, I’ll first reply this one:
The translated/proofread badges you see in the Progress of Translation section are provided by the Badges & Status Images application. This application provides two resources for each project where it’s enabled (take ros2-docs-l10n for example):
The badges are supposed to read the translation and proofreading progress for each language from the JSON resource. However, for some reason, the JSON resource is quite unstable, which is why the badges are showing incorrect information.
I’ve already reported this issue to the Crowdin Support Team, and after a discussion, they confirmed it’s a bug. They will notify me via email once they find the cause and fix the issue. For now, to see the actual translation and proofreading progress for each language, please refer to the PNG resource:
The ros2-docs-l10n project was created out of personal interest. However, if the OSRA offers relevant Grants or Sponsorship programs, I would be interested in applying for support for my ongoing l10n projects.
Besides, I plan to continue creating and publishing localization projects for Sphinx-based open source documentation at my own pace, as listed in the Projects Index. These projects include, but are not limited to:
If OSRA finds those l10n projects suitable for sponsorship and requires an appropriate sponsorship channel (e.g., Open Collective), please feel free to contact me.
Ultimately, the scripts in the docsbuild-scripts repository fetch the translated .po files from python-docs-xx and perform a unified build and release. My l10n project essentially consolidates the operations mentioned above into a single repository. You can basically think of my l10n project as a self-sufficient ecosystem.
As for how the upstream can integrate the .po files I maintain downstream into its building workflow, that’s something the upstream maintainers will have to brainstorm. The tools used for automated Sphinx documentation builds vary from project to project: some use GitHub Actions, some use Read the Docs, some use use GitLab CI/CD, ans so on. It would be a huge burden for me to design and maintain a multilingual documentation workflow for every single upstream project. I think the only thing I can do right now is to deploy the translated .po files to the corresponding po/${VERSION} branch, allowing upstream to easily fetch them using the following command:
I want to highlight this. I am generally worried about the overhead and effort of this can/will require for our community.
Part of what I’m concerned about is that you’re building the separate “ecosystem” which is isolated from the existing ecosystem. And I don’t understand how this is considered self sufficient without a large community effort to maintain the work.
With respect to this, trust and transparency are very important to the community. For any unofficial externally hosted content it should be clearly documented it’s provenance. For example these localized versions of the documentation should have a very clear header at the top saying that they are the product of your above process with links to get to the source and the process. And it should be clear to the reader who is maintaining these documents, right now there’s nothing to indicate to a reader that these are not the official docs please make sure to add that. You could even link to the original source from each page which would make it clear where the original comes from.
This is especially important for high trust documents such as the installation instructions. A bad translation at that stage can potentially fully compromise the users system. The core maintainers pay a lot of attention to changes in that area, and if there’s a separate review process for the translations it adds another layer of risk.
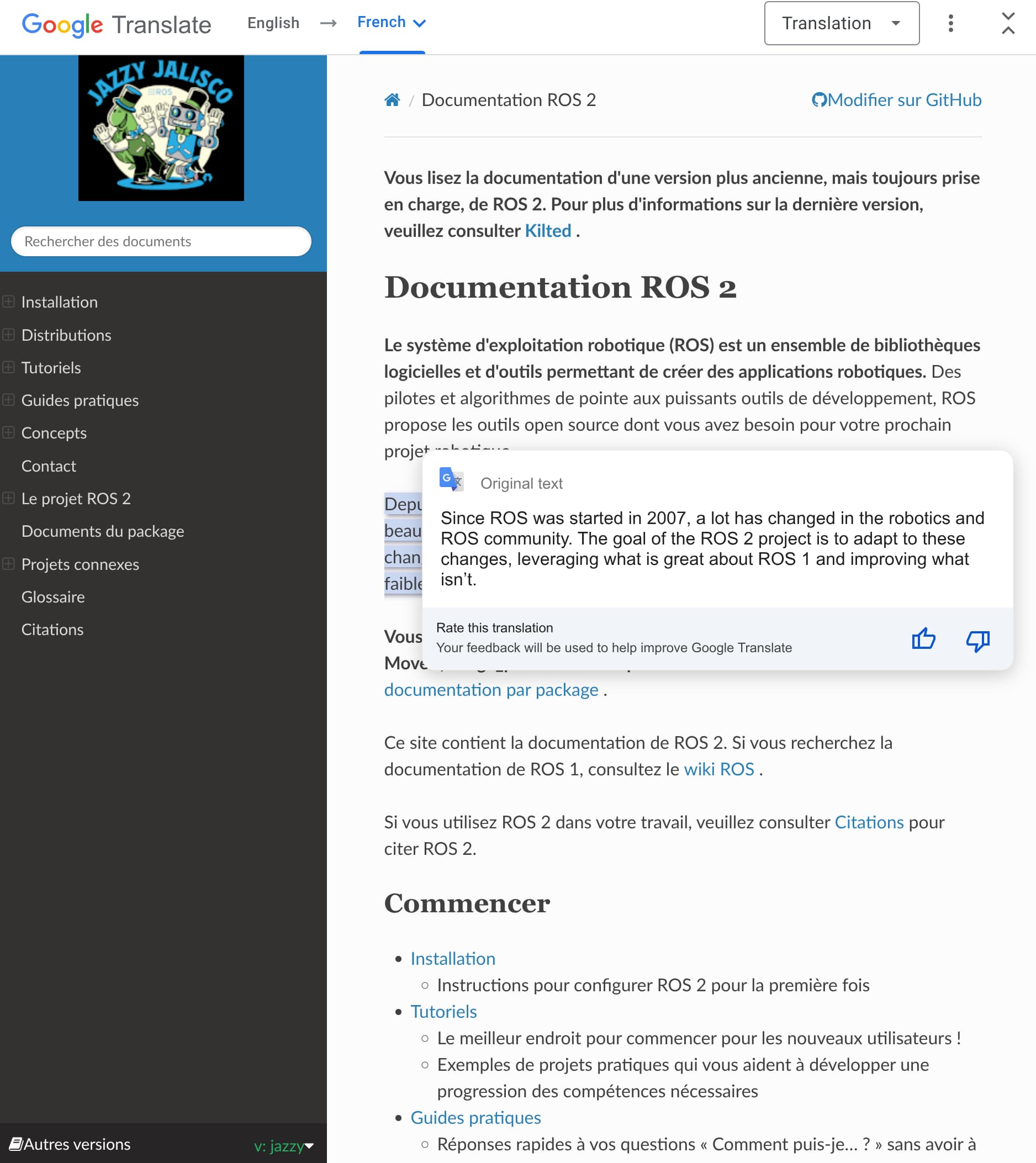
Returning to the topic of the effort though I’d like to understand how this performs compared to leveraging fully automated systems. We can get approximately complete auto translations from various services. One I’m familiar with is Google Translate and it can give a pretty complete result already.
The google Translate version also ahs the benefit of having the version switching menu in the bottom left successfully translated which I’m assuming that your build isn’t doing the multi-version build of the documentation to get the version switching menu and is instead doing the multi language selector which appears in the bottom right. And with that we’re looking at currently 2 partial translations, where Google Translate will provide us with many more languages that we can even think of potentially maintaining.
For example I reviewed the French version of Jazzy which looks reasonable and is just one of more than 100 languages which it can support.
It might be more sustainable for us to consider adding convenient links to a service like google translate in a convenient menu.
I understand that doing our own translations will potentially provide better translations. However those benefits come at the significant cost of maintaining the translations. And especially with evolving documentation the translation costs are not a one time thing but an ongoing burden. Whereas the automated translations have minimal costs but are less customizable.
My above discussion is generally about just a manually maintained translations versus automated. As we look to do this for the project I’d like to understand why you’ve chosen to use Crowdin. @Katherine_Scott has raised some good concerns about it. As an open source project we generally work hard to make sure that all of our tools are locally reproducible at no cost for individual users, companies, and definitely contributors. Can you explain how you selected this platform and why you’re proposing this mechanism for managing the po files versus any of the other potential ones. If we as a community are going to invest time and energy into this we want to make sure it’s the best choice.
One other aspect of this is that if we’re setting up localization infrastructure for this set of documentation, we should also think about how it can also scale to cover the generated documentation per package as well as providing the same capability to the executables and other web resources. And although we don’t necessarily deploy all of these immediately we should understand our path to doing all of the systems in the same or similar manner so that we can provide the same experience for contributors who can help with the effort on both sides and avoid duplicating efforts or requiring using multiple different processes.
@tfoote You mentioned a lot of viewpoints. But let me explain this part first:
Regarding the “self-sufficient” ecosystem, what I mean is that operations such as generating and updating .po files, uploading sources to Crowdin, downloading translations from Crowdin, and building translated documents can all be completed independently within the ros2-docs-l10n project.
This means that upstream projects don’t need to write specific scripts or workflows to handle these tasks. They just need to focus on maintaining the English sources. As for the translation contributions on Crowdin, those will, of course, still require volunteers from each language community.
In short, I chose Crowdin mainly because its Open Source License (OSL) has more lenient and flexible eligibility requirements.
When I was selecting a TMS platform, I focused on three options: Transifex, Weblate, and Crowdin. While all three platforms offer an OSL, Transifex and Weblate’s OSLs required me to be a member of the upstream project’s maintenance team with administrative access. In other words:
To apply for OSL for cmake-docs-l10n, I would have to be a member of the CMake team with administrative access.
To apply for OSL for python-docs-l10n, I would have to be a member of the Python team with administrative access.
To apply for OSL for ros2-docs-l10n, I would have to be a member of the ROS 2 team with administrative access.
…and so on.
This was simply not a realistic option.
However, Crowdin’s OSL does not have this requirement. It essentially only requires that my xxx-docs-l10n project is open-source and non-profit. Furthermore, after hearing about my localizethedocs initiative and discussing it internally, the Crowdin Support Team was very kind and offered me an extended trial period. This allowed me to familiarize myself with its platform and its CLI tool, which is why I ultimately chose Crowdin for my TMS platform.
I’ve asked a similar question to the CMake team before:
The conclusion I got was that I didn’t need to overthink this part. According to the CMake documentation’s license, I only need to retain the original license and copyright information in my translated documents. The documentation built by Sphinx with .po files keep this information. From the CMake team’s reply, it seems that simply keeping the Copyright and License information on the page is sufficient to indicate the provenance. But still, I would like to confirm what the exact requirements of the ROS 2 documentation are.
On the other hand, I’d like to know what the ROS 2 team thinks of the Chinese documentation for ROS 2 created by Fish ROS. Does this kind of translated documentation meet the ROS 2 team’s requirements for provenance? Although I couldn’t find its open-source repository, it appears they didn’t use the .po file maintenance method that I did. Instead, they seem to have directly modified the source files (.rst or .md) for translation.
The main goal of my project is to directly translate the generated .po files, not to modify the .rst files directly. This allows the upstream project, or anyone, to use the prepared .po files to build the translated documentation. For this reason, adding content to the original .rst files is honestly a bit inconvenient.
Regarding Bad Translations:
I think we can add a note in the ros2-docs-l10n repository’s README.md file, telling readers to primarily use the English documentation or the upstream project as a reference.
If the ROS team strongly insists on adding the information above, I can add a note about this in my ros2-docs-l10n repository’s README.md. For example:
We are not the CMake project. They have their own policies. Yes, the license only requires you to maintain the license and copyright information. However, we are asking you to make it much clearer to your site’s readers what they are reading and where the source documentation lives, in order to prevent confusion over which is the “true” documentation - especially when there are inaccuracies in the translation or the translated version is out of date.
This is the sort of thing you need to have, but it needs to be clearly displayed on every documentation page - such as in a one-line header at the top. No one looking at documentation is going to go and read the README file in the source repository.
Besides, I’d like to know the relationship between Fish ROS and the ROS team. The ROS Chinese documentation created by Fish ROS doesn’t seem to provide this information. I was wondering if Fish ROS has received official authorization from the ROS team, which might explain why they don’t need to add such details. If so, I’d like to try to apply for similar authorization. After all, the goal of my localizethedocs initiative is to become an officially designated translation project for open-source documents.
you will find that the scripts and workflow file structures used in them are very similar. Some scripts are even completely identical, with the flyout and modules, and the ci-common repositories being shared. Essentially, I can easily create l10n projects for any Sphinx-based document using a similar template. However, I’d like to take this opportunity to make some suggestions to the ROS team regarding the projects they currently maintain:
From the REP’s rep-0001.rst, it’s clear that REPs were originally generated using the format and build tools from PEPs:
The REP process is based on the Python PEP process. We are thankful to the Python PEP contributors for providing a process, tools, and templates for community participation in a design process.
However, since PR1932, PEPs has started using Sphinx to build its documentation. As a side note, the python-peps-l10n project is currently in incubation. Here is a preview screenshot of its locally built documentation:
Therefore, if REPs could adopt the current Sphinx structure of PEPs to build its documentation, I could theoretically create a localization project called ros-reps-l10n using a structure similar to the incubating python-peps-l10n.
Suggestion 2: Improve rosdoc2 by jupyter-book
I believe this section is referring to the rosdoc2 project. From its README.md, this command-line tool is a document generator designed by the ROS team specifically for ROS packages (e.g., rclcpp, rclpy). It appears to automatically provide default Doxyfile and conf.py configuration files if the project author does not provide custom ones. Its internal processing logic should use the Breathe approach:
Run doxygen with Doxyfile to generate xml files from C++ comments.
Run sphinx-build with conf.py to build the ROS package documentation.
It can even use a dedicated configuration file, rosdocs2.yml, to control how the package documentation is generated.
This design reminds me of the jupyter-book tool designed for the Jupyter project. This command-line tool essentially wraps Sphinx and has dedicated configuration files (_config.yml and _toc.yml). However, if we carefully read its documentation and its .readthedocs.yml file, we will find that we can actually use the jupyter-book config command to first generate conf.py and then run the sphinx-build command to build the documentation. This also explains why the Jupyter Book project can be hosted on Read The Docs, since it is essentially built using the logic of a Sphinx project:
Read the Docs is a web service for hosting documentation online. They offer free web hosting for open source projects, sustained by ethical advertising that is inserted into pages. These ads can also be removed with a small monthly payment to help sustain the project.
Suppose that rosdoc2 could implement a similar functionality to jupyter-book. For example:
Run the rosdoc2 config command to generate the necessary Doxyfile and conf.py.
Run the doxygen command to generate the required xml files (if necessary).
Run the sphinx-build command to build the documentation.
Then, theoretically, I could create localization projects for all documents generated by rosdoc2, such as:
However, rclpy seems to provide a custom conf.py file and doesn’t need to use Breathe to process C++ comments. Therefore, I can actually create rclpy-docs-l10n directly using a structure similar to ros2-docs-l10n.
There isn’t one. The nature of open source means that as long as they stay within the license we cannot control what someone else does, but we can ask that they act in a constructive way as part of the community - as we are doing for you.
 Preview: ros2-docs-l10n
Preview: ros2-docs-l10n Crowdin: ros2-docs-l10n
Crowdin: ros2-docs-l10n GitHub: ros2-docs-l10n
GitHub: ros2-docs-l10n






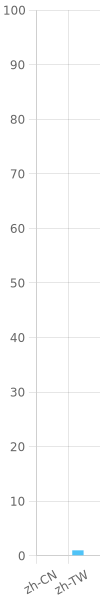{kind=link}