Posted by @cwrx777:
Hi,
I’m checking with the community if they have experienced not being able to echo /fleet_states after some time. /door_states and my custom topic that’s published by the fleet adapter periodically are still able to echo.
OS: Ubuntu 22.04
rmf branch: 22.09
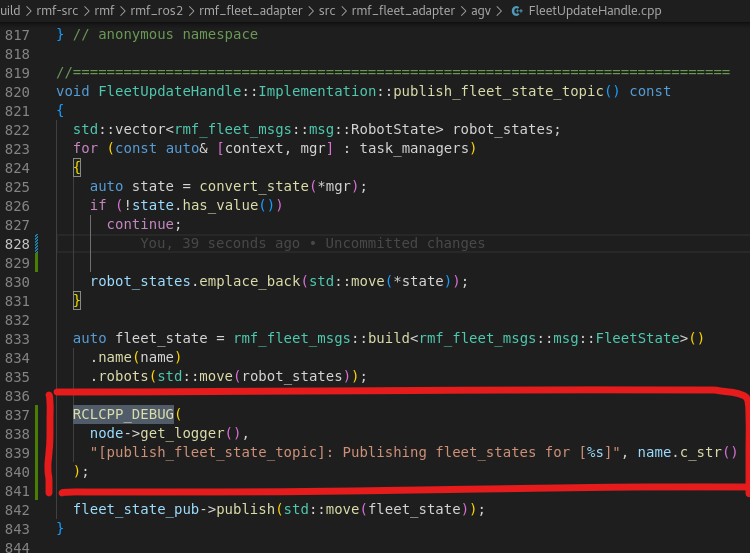
To troubleshoot this issue, i added some debug logs in FleetUpdateHandle.cpp in the following places as follows:
method: publish_fleet_state_topic
method: update_fleet_state
When /fleet_states is not received in ros2 topic echo, I noticed that the log message in publish_fleet_state_topic and in update_fleet_state method were not printed. Does it seem that the wall timer here and here failed?
However, a custom topic that I published from within this code block can be echoed.
Edited by @cwrx777 at 2023-04-19T09:03:28Z
Posted by @cwrx777:
Additional information:
I run the following using iron_20231229 release.
When /fleet_states are not published, the purple icon in rviz will not be shown. See the video below from 0:18 to 0:48.
The terminal beside rviz shows ros2 topic hz /fleet_states and ros2 topic echo /fleet_states | grep nanosec.
Posted by @mxgrey:
I don’t think the wall timer is at fault. Based on the video I suspect something is blocking up the main event loop for longer than it should.
Are you doing anything in particular around the same time that this is happening, for example submitting new task requests? In iron and older releases, task planning gets done inside the main event loop, so if there are many tasks queued up then submitting a new task can clog up the main event loop for an inordinate amount of time. This is fixed in the latest main branch.
Other than that, the only thing I can think of that tends to block up a thread is traffic planning and negotiation, but I wouldn’t suspect those of being problems because:
- Those have been decoupled from the main event loop for a long time now, well before the
humble release.
- There is some risk that planning or negotiation can occupy the thread that gets used by the main event loop, but the probability is low unless you are using a computer with a very small number of threads.
- This is a very small nav graph so motion planning should be almost instantaneous.
- There are only two robots so negotiation should be almost instantaneous.
Is there anything unusual about the computer you are running this on? Like having very few CPU cores?
my custom topic that’s published by the fleet adapter periodically are still able to echo
Can you link us to where this topic is being published and how it gets triggered? When I try to go to the provided link I get a 404 error.
If the publishing is triggered by a wall timer that was with the fleet adapter node but is still being published while the fleet states are not then that would disprove my hypothesis. All the wall timers created by the adapter node will only be triggered within the thread of the main event loop.
Edited by @mxgrey at 2024-05-28T22:52:18Z
Posted by @cwrx777:
Hi @mxgrey ,
Thanks for the pointers.
I’ll increasing the number of cores to the my VM.
My custom topic is published from within this link
def update(self):
while rclpy.ok():
self.position = self.get_position()
self.battery_soc = self.get_battery_soc()
if self.update_handle is not None:
self.update_state()
self.publish_custom_topic()
sleep_duration = float(1.0/self.update_frequency)
self.sleep_for(sleep_duration)
The fleet_state hung up was observed while robots were performing tasks and intermittently when there was conflict/negotiation.
I’m not sure if it’s related, sometimes there was no more follow_new_path command triggered for the robots. And after a long delay, the robots would get the command at the same time.
I also observe sometimes robots keep getting replanned to go to the same position/waypoint.
Would it help if the wall timer is using a different callback group and the fleet adapter Executor is using MultiThreadedExecutor?
Is fleet_states topic used by other nodes to know the robot current position and traffic control/planning or other purpose?
For my understanding, how and when follow_new_path in the python fleet adapter get called? Is there some kind of synchronization with other robots/fleets, or with a some kind of traffic schedule before the next follow_new_path gets called?
Posted by @cwrx777:
I have increased the number of vCPU to the VM to 8, previously was 4.
release: iron 20231229
code modification:
void FleetUpdateHandle::Implementation::publish_fleet_state_topic() const
{
std::vector<rmf_fleet_msgs::msg::RobotState> robot_states;
for (const auto& [context, mgr] : task_managers)
{
auto state = convert_state(*mgr);
if (!state.has_value())
continue;
robot_states.emplace_back(std::move(*state));
}
auto fleet_state = rmf_fleet_msgs::build<rmf_fleet_msgs::msg::FleetState>()
.name(name)
.robots(std::move(robot_states));
RCLCPP_INFO(
node->get_logger(),
">>>>>>>>> fleet_state_pub->publish(std::move(fleet_state))");
fleet_state_pub->publish(std::move(fleet_state));
}
here are the commands I used :
ros2 launch rmf_demos_gz_classic office.launch.xml
ros2 run rmf_demos_tasks dispatch_patrol -F tinyRobot -R tinyRobot1 -p lounge hardware_2 pantry supplies --use_sim_time
ros2 run rmf_demos_tasks dispatch_patrol -F tinyRobot -R tinyRobot2 -p lounge hardware_2 pantry supplies --use_sim_time
video:
from 00:18
Posted by @mxgrey:
My custom topic is published from within this link
Based on the code snippet it looks like you’re using rclpy and an event loop within Python to publish the custom message. In that case it will be able to publish even if the C++ main event loop in rmf_fleet_adapter is blocked. So I think there is indeed something blocking the main event loop.
how and when follow_new_path in the python fleet adapter get called?
This function will be called in the following situations:
- A new plan was generated for the robot because
- the robot’s task needs it to go to a new place, or
- a negotiation was finished
- The robot is done waiting for something to happen such as
- a door to open
- a lift to arrive
- another robot to pass
The follow_new_path function does block the C++ main event loop which is why all the examples we provide will quickly offload the execution of following the path into a separate Python thread. If you’re using rmf_demos_fleet_adapter without significant modifications then this should be okay.
the fleet adapter Executor is using MultiThreadedExecutor?
We can’t use a multi-threaded executor in the C++ implementation without adding an enormous number of mutexes throughout the codebase and using them very meticulously. This would give us a very high risk of data races (which can lead to undefined behavior and program crashes) and generally make the implementation even harder to work with than it already is.
This is a big part of why we’re migrating the next generation effort to Bevy which will be able to do high performance multi-threading without having these risks.
video: from 00:18
In this example I can confidently say that the system got jammed up by the negotiation. This particular type of negotiation, where two robots are suddenly head-to-head and one needs to back off so that the other can get out of the way, is a particularly challenging situation for the current system to work out. I’m not very surprised that all the threads would be eaten up by this, especially when it’s limited to 8 threads. (Another benefit of Bevy is that we’ll be able to limit how many threads are used by the planners and negotiations, so the main event loop doesn’t get pushed down by them.)
What I find most strange about the video is that tinyRobot1 seemed to teleport at t=0:10 to suddenly be blocking tinyRobot2. The negotiation system works best when it can anticipate conflicts in advance and prevent them from ever occurring. I’m not sure how that teleportation was possible in the first place.
Edited by @mxgrey at 2024-05-29T05:09:33Z
Posted by @cwrx777:
What I find most strange about the video is that tinyRobot1 seemed to teleport at t=0:10 to suddenly be blocking tinyRobot2. The negotiation system works best when it can anticipate conflicts in advance and prevent them from ever occurring. I’m not sure how that teleportation was possible in the first place
The 'teleport’at 00:10 was because I’ve shortened the video to the time of interest. I should’ve mentioned this earlier.
FYI, The demo captured in the video was done using the rmf_demos_fleet_adapter in the iron 20231329 release.
Posted by @mxgrey:
In this case the time period that was cut out might have been very informative. It looks like tinyRobot2 was supposed to have moved out of the charger but somehow remained there until tinyRobot1 was blocking it. I can’t tell if the simulated robot was unresponsive or if the traffic negotiation was misbehaving to get it stuck like that.
But I think the main issue here is that the robots are being commanded to go to the same waypoints at the same time, and those waypoints don’t have good traffic flow to let the robots get around each other.
We intend to fix this with the reservation system which is in a testing phase right now, but in the meantime this kind of issue can be mitigated with two techniques:
- Have uni-directional entry and exit lanes for the target waypoints that allow the robots to pass each other.
- In addition to (1), strategically use mutex groups on the lanes and waypoints.
In this case (1) should be enough, but adding (2) will help keep the flow extra safe.
Posted by @cwrx777:
Hi @mxgrey
Here is the more complete video:
https://github.com/open-rmf/rmf/assets/3224215/b2295729-bec8-4691-83a8-ce0aa0795ad9
The main issue that we are facing is the frequent pauses, long delay with the robot movement, the follow_new_path comand doesn’t get called soon after the earlier one is completed. i have created another discussion (open-rmf#470) to understand how the follow_new_path gets called.
Posted by @mxgrey:
These cases tend to be situational and can typically be managed with with explicit traffic flows, i.e. separate uni-directional enter and exit lanes.
The worst cases usually arise from multiple robots trying to approach the same destination at the same time. This is something we’re actively working to fix with the reservation system, and we’re attempting to get a basic prototype into the current generation of RMF, while a more sophisticated implementation will be available in the next generation.